
Notice
Recent Posts
Recent Comments
Link
초보 개발자의 일기
Pandas - Selection 본문
데이터 선택
Getting
데이터 프레임의 단일 컬럼(column)을 선택하여 Series를 생성한다. ( ↓예시용 데이터 프레임)

열 인덱싱
df['A'] # column 인덱싱 - 인덱스도 함께 출력됨2013-01-01 -0.824017
2013-01-02 -0.585061
2013-01-03 1.296661
2013-01-04 -1.111253
2013-01-05 0.963859
2013-01-06 -0.778794
Freq: D, Name: A, dtype: float64
행 인덱싱
데이터프레임명[시작행:종료행] : 종료행 이전까지 출력된다.
df[0:3] # row 인덱싱 
특정 행 값 인덱싱
데이터프레임명[시작행 인덱스 : 종료행 인덱스] : 종료행을 포함하여 출력된다.
df['20130102':'20130104']
Selection by label : loc[]
행과 열의 이름으로 특정 데이터를 가져오는 방법이다.
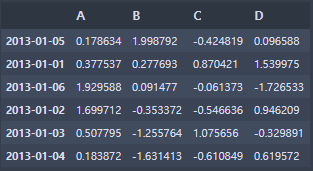
- 좌측의 데이터프레임은 날짜 형식의 인덱스를 가지고 있다.
- 인터프리터에 dates[0]을 입력하고
Timestamp('2013-01-01 00:00:00', freq='D') 이 출력된다. - 인터프리터에 df.loc[dates[0]]을 입력하고 실행하면 첫번째 인덱스의 행 값들이 출력된다.
- loc를 이용하여 특정 열의 모든 행을 추출하는 것도 가능하다.
df.loc[dates[0]] # 첫번째 인덱스의 행 출력A 0.377537
B 0.277693
C 0.870421
D 1.539975
Name: 2013-01-01 00:00:00, dtype: float64
df.loc[:, ['A', 'B']] # A열과 B열의 모든 행 추출
df.loc['20130102':'20130104', ['A', 'B']] # A열과 B열의 특정 행 추출
df.loc[dates[0], 'A']
df.at[dates[0], 'A'] # 같은 결과가 출력된다.0.37753714341895384
0.37753714341895384
Selection by position
행과 열의 특정 위치를 지정해 값을 가져오는 방법이다.
df.iloc[3] # i = index # 특정 행 값들 가져오기A 0.183872
B -1.631413
C -0.610849
D 0.619572
Name: 2013-01-04 00:00:00, dtype: float64
df.iloc[3:5, 0:2] # 특정 행, 열 값들 가져오기
df.iloc[[1, 2, 4], [0, 2]]
Boolean indexing
조건에 맞는 값을 가져오는 방법이다.
df[df['A'] > 0] # 'A'열에 있는 값이 0보다 큰 값 가져오기
df[df > 0] # 데이터가 0보다 큰 값 가져오기
※ 열 삽입
df2 = df.copy()
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
df2
isin
특정 값으로 필터링
df2[df2['E'].isin(['two', 'four'])]
Setting
s1 = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range('20130102', periods=6))
s1판다스 date_range 메소드를 사용하여 지정한 날짜부터 periods만큼 날짜 데이터(timestamp)를 생성한다.
2013-01-02 1
2013-01-03 2
2013-01-04 3
2013-01-05 4
2013-01-06 5
2013-01-07 6
Freq: D, dtype: int64
array * len
df.loc[:, 'D'] = np.array([5] * len(df))
df데이터프레임의 행 수만큼 반복하여 값을 생성, 데이터프레임에 입력한다.
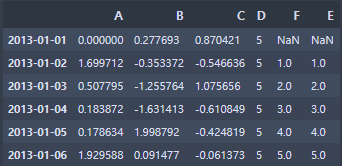
연산
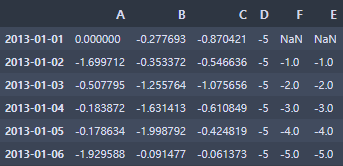
df2 = df.copy() # df2는 df 복사한 데이터프레임
df2[df2 > 0] = -df2df2의 0보다 큰 값들에 전부 마이너스를 곱한다.
<bound method Series.drop of 2013-01-01 NaN
2013-01-02 1.0
2013-01-03 2.0
2013-01-04 3.0
2013-01-05 4.0
2013-01-06 5.0
Freq: D, Name: E, dtype: float64>
※ 10 minutes to pandas를 바탕으로 한 학습 기록입니다 ※
'소소한 공부 일기 > 데이터 분석' 카테고리의 다른 글
| Pandas - Operations (0) | 2021.05.08 |
|---|---|
| Pandas - Missing data (0) | 2021.05.08 |
| Pandas - Viewing data (0) | 2021.05.08 |
| Pandas - Object creation (0) | 2021.05.05 |
| NumPy - 선형대수 연산 (0) | 2021.05.05 |
'소소한 공부 일기/데이터 분석' Related Articles
more




Comments